在当前大数据时代,Hadoop已成为一种非常流行的分布式计算框架。本文将介绍如何在Win10操作系统上安装和配置Hadoop,帮助读者在自己的个人计算机上搭建一个高效的大数据处理环境。

准备工作
在安装Hadoop之前,需要确保已经安装了JavaDevelopmentKit(JDK)并正确配置了环境变量。读者可以从Oracle官方网站上下载JDK安装包,并按照官方文档进行安装和配置。
下载Hadoop二进制文件
访问ApacheHadoop官方网站,下载最新版本的Hadoop二进制文件。读者可以选择合适的版本,根据自己的需求选择适合的二进制发行版。

解压Hadoop二进制文件
将下载的Hadoop二进制文件解压到一个合适的目录中。建议将解压后的文件夹命名为hadoop,并将其移动到C盘根目录下,以便后续操作。
配置Hadoop环境变量
打开系统的环境变量配置页面,添加Hadoop的bin目录路径到系统的Path变量中,这样可以在任意位置使用Hadoop命令。
配置Hadoop的核心文件
进入hadoop文件夹,打开etc文件夹,找到hadoop-env.cmd(对于Windows系统)或hadoop-env.sh(对于Linux系统)文件,并根据需要修改其中的参数,如Java安装路径等。
配置Hadoop的主节点和从节点
在hadoop文件夹中找到etc文件夹下的core-site.xml、hdfs-site.xml和mapred-site.xml等配置文件,根据自己的需求进行相应的配置。比如,指定主节点和从节点的IP地址、端口等信息。
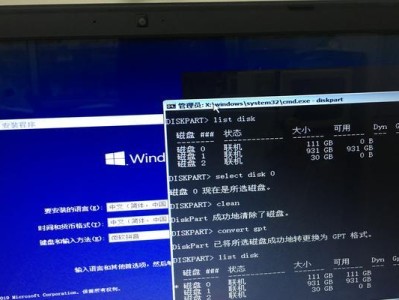
格式化Hadoop的文件系统
运行以下命令,在命令行中输入“hdfsnamenode-format”,该命令将会格式化Hadoop的文件系统,准备好进行后续的使用。
启动Hadoop集群
运行以下命令,在命令行中输入“start-all.cmd”启动Hadoop集群,这将会启动所有的Hadoop守护进程,并使得集群处于可用状态。
验证Hadoop安装是否成功
在浏览器中输入http://localhost:50070,打开Hadoop集群的Web界面,如果能够正常显示出Hadoop的文件系统信息,则说明安装成功。
上传和处理数据
使用hdfs命令行工具或者Hadoop集群的Web界面,可以上传数据到Hadoop的文件系统中,并且可以使用MapReduce或其他Hadoop生态系统的工具进行数据处理。
监控和管理Hadoop集群
通过Hadoop集群的Web界面,可以实时监控和管理Hadoop集群的状态,包括节点的健康状况、任务的执行情况等。
调优和优化Hadoop性能
根据实际需求,可以对Hadoop集群进行调优和优化,比如调整数据块大小、增加节点数量等,以提高Hadoop的性能和吞吐量。
故障排除和常见问题解决
在使用Hadoop的过程中,可能会遇到各种问题和故障。本将介绍一些常见问题,并提供相应的解决方法,帮助读者快速排除故障。
升级和维护Hadoop
当新版本的Hadoop发布时,需要进行升级操作。本将介绍如何升级Hadoop,并给出一些维护Hadoop集群的实用技巧。
本文介绍了在Win10操作系统上安装和配置Hadoop的详细步骤,包括准备工作、下载和解压文件、配置环境变量和核心文件、启动集群以及上传和处理数据等。通过本文的指导,读者可以在自己的个人计算机上搭建一个高效的Hadoop大数据处理环境。
结尾
Hadoop是处理大数据的重要工具,在Win10上安装和配置Hadoop可以帮助我们搭建一个强大的大数据处理环境。通过本文所介绍的详细步骤,读者可以轻松地在自己的电脑上安装和配置Hadoop,并开始进行大数据处理的工作。希望本文能够对读者有所帮助,让大家能够更好地利用Hadoop来处理和分析海量的数据。